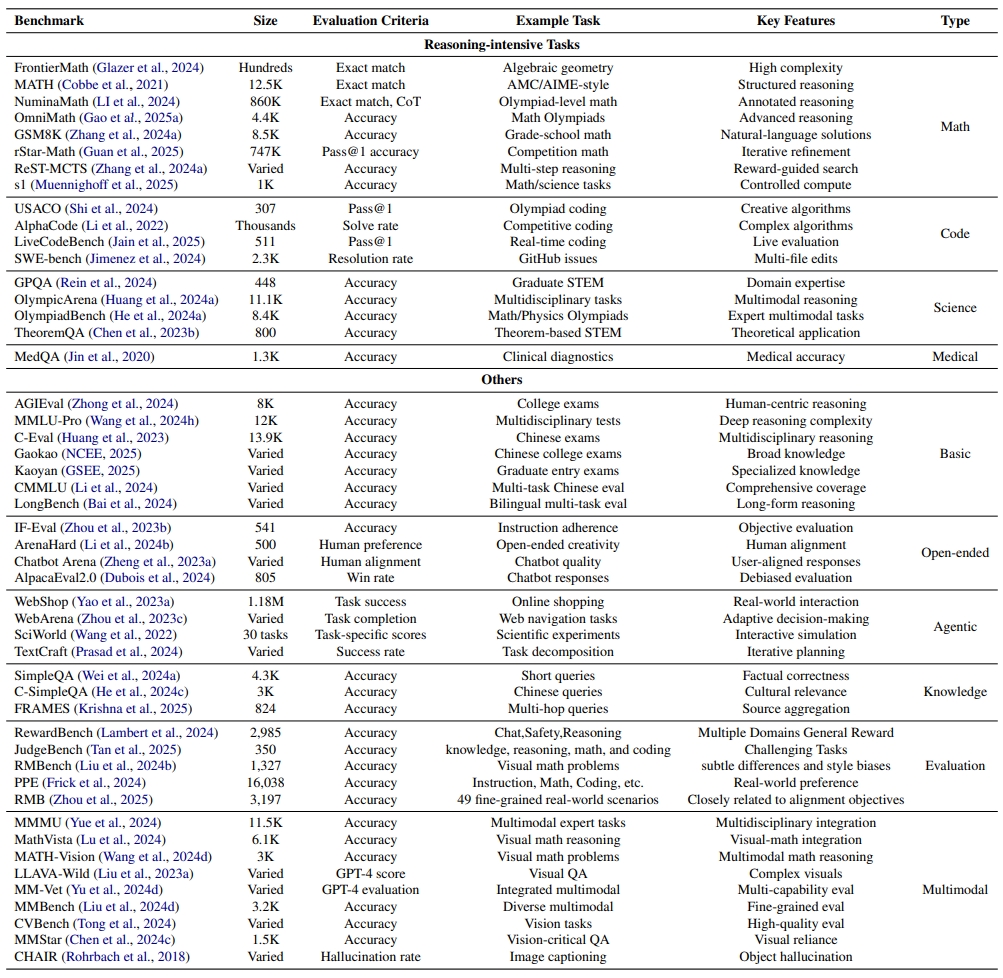
As enthusiasm for scaling computation (data and parameters) in the pretraining era gradually diminished, test-time scaling (TTS), also referred to as ``test-time computing'' has emerged as a prominent research focus. Recent studies demonstrate that TTS can further elicit the problem-solving capabilities of large language models (LLMs), enabling significant breakthroughs not only in specialized reasoning tasks, such as mathematics and coding, but also in general tasks like open-ended Q&A. However, despite the explosion of recent efforts in this area, there remains an urgent need for a comprehensive survey offering a systemic understanding. To fill this gap, we propose a unified, multidimensional framework structured along four core dimensions of TTS research: what to scale, how to scale, where to scale, and how well to scale. Building upon this taxonomy, we conduct an extensive review of methods, application scenarios, and assessment aspects, and present an organized decomposition that highlights the unique functional roles of individual techniques within the broader TTS landscape. From this analysis, we distill the major developmental trajectories of TTS to date and offer hands-on guidelines for practical deployment. Furthermore, we identify several open challenges and offer insights into promising future directions, including further scaling, clarifying the functional essence of techniques, generalizing to more tasks, and more attributions.
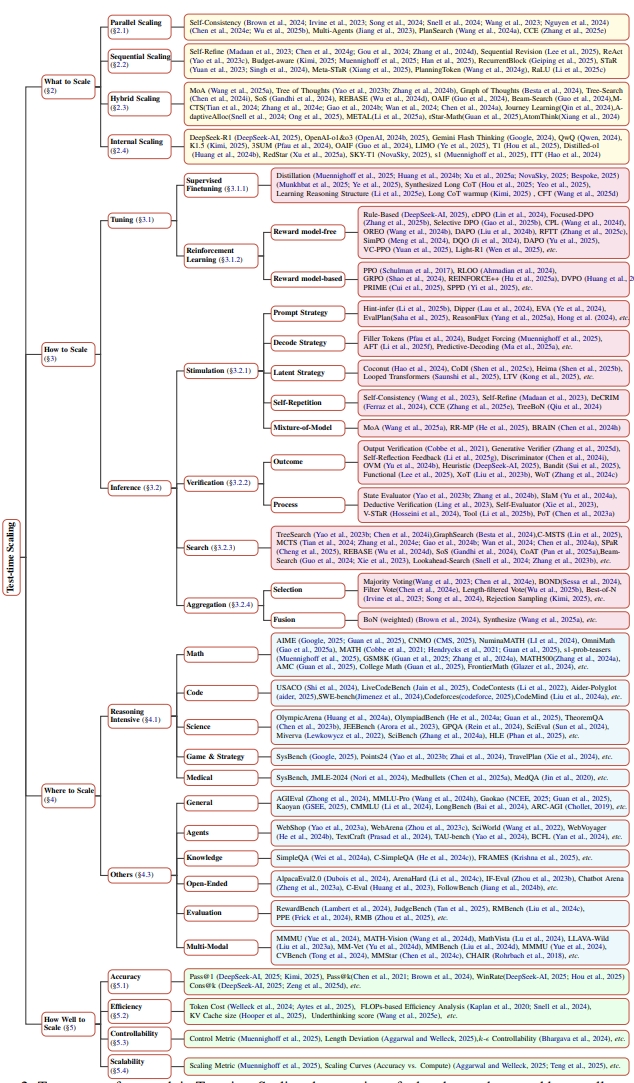



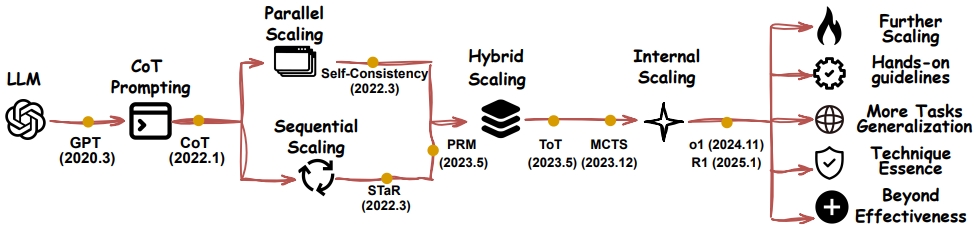
“What to scale” refers to the specific form of TTS that is expanded or adjusted to enhance an LLM’s performance during inference.
Test-time Scaling Paper Summary
| Method (PapersTitles) | What | How → | Where | How Well | |||||
|---|---|---|---|---|---|---|---|---|---|
| SFT | RL | STI | SEA | VER | AGG | ||||
|
Scaling llm test-time compute optimally can be more effective than scaling model parameters.
|
Parallel, Sequential |
✗ | ✗ | ✗ | Beam, LookAhead |
Verifier | (Weighted) Best-of-N, Stepwise Aggregation |
Math | Pass@1, FLOPsMatched Evaluation |
| Multi-agent verification: Scaling test-time compute with goal verifiers ., |
Parallel | ✗ | ✗ | Self-Repetition | ✗ | Multiple-Agent Verifiers |
Best-of-N | Math, Code, General |
BoN-MAV (Cons@k), Pass@1 |
| Evolving Deeper LLM Thinking , |
Sequential | ✗ | ✗ | Self-Refine | ✗ | Functional | ✗ | Open-Ended | Success Rate, Token Cost |
| Meta-reasoner: Dynamic guidance for optimized inference-time reasoning in large language models , |
Sequential | ✗ | ✗ | CoT + Self-Repetition |
✗ | Bandit | ✗ | Game, Sci, Math |
Accuracy, Token Cost |
| START: Self-taught reasoner with tools , |
Parallel, Sequential |
Rejection Sampling | ✗ | Hint-infer | ✗ | Tool | ✗ | Math, Code |
Pass@1 |
| " Well, Keep Thinking": Enhancing LLM Reasoning with Adaptive Injection Decoding , |
Sequential | ✗ | ✗ | Adaptive Injection Decoding |
✗ | ✗ | ✗ | Math, Logical, Commonsense |
Accuracy |
| Chain of draft: Thinking faster by writing less , |
Sequential | ✗ | ✗ | Chain-of-Draft | ✗ | ✗ | ✗ | Math, Symbolic, Commonsense |
Accuracy, Latency, Token Cost |
| rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking , |
Hybrid | imitation | ✗ | ✗ | MCTS | PRM | ✗ | Math | Pass@1 |
| Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling , |
Parallel, Hybrid |
✗ | ✗ | ✗ | DVTS, Beam Search |
PRM | Best-of-N | Math | Pass@1, Pass@k, Majority, FLOPS |
| Tree of thoughts: Deliberate problem solving with large language models , |
Hybrid | ✗ | ✗ | Propose Prompt, Self-Repetition |
Tree Search | Self-Evaluate | ✗ | Game, Open-Ended |
Success Rate, LLM-as-a-Judge |
| Mindstar: Enhancing math reasoning in pre-trained llms at inference time , |
Hybrid | ✗ | ✗ | ✗ | LevinTS | PRM | ✗ | Math | Accuracy, Token Cost |
| Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for LLM Problem-Solving , |
Hybrid | ✗ | ✗ | ✗ | Reward Balanced Search |
RM | ✗ | Math | Test Error Rate, FLOPs |
| Reasoning-as-Logic-Units: Scaling Test-Time Reasoning in Large Language Models Through Logic Unit Alignment , |
Hybrid | ✗ | ✗ | Self-Refine | Control Flow Graph | Self-Evaluate | Prompt Synthesis | Math, Code |
Pass@1 |
| PlanGEN: A Multi-Agent Framework for Generating Planning and Reasoning Trajectories for Complex Problem Solving , |
Parallel, Hybrid |
✗ | ✗ | MoA | ✗ | Verification Agent | Selection Agent | Math, General, Finance |
Accuracy, F1 Score |
| A Probabilistic Inference Approach to Inference-Time Scaling of LLMs using Particle-Based Monte Carlo Methods , |
Hybrid | ✗ | ✗ | ✗ | Particle-based Monte Carlo |
PRM + SSM | Particle Filtering | Math | Pass@1, Budget vs. Accuracy |
| Archon: An Architecture Search Framework for Inference-Time Techniques , |
Hybrid | ✗ | ✗ | MoA, Self-Repetition |
✗ | Verification Agent, Unit Testing (Ensemble) |
Fusion | Math, Code, Open-Ended |
Pass@1, Win Rate |
| Wider or deeper? scaling llm inference-time compute with adaptive branching tree search , |
Hybrid | ✗ | ✗ | Mixture-of-Model | AB-MCTS-(M,A) | ✗ | ✗ | Code | Pass@1, RMSLE, ROC-AUC |
| Thinking llms: General instruction following with thought generation , |
Internal, Parallel |
✗ | DPO | Think | ✗ | Judge Models | ✗ | Open-Ended | Win Rate |
| Self-Evolved Preference Optimization for Enhancing Mathematical Reasoning in Small Language Models , |
Internal, Hybrid |
✗ | DPO | Diversity Generation | MCTS | Self-Reflect | ✗ | Math | Pass@1 |
| MA-LoT: Multi-Agent Lean-based Long Chain-of-Thought Reasoning enhances Formal Theorem Proving , |
Internal, Sequential |
imitation | ✗ | MoA | ✗ | Tool | ✗ | Math | Pass@k |
| Offline Reinforcement Learning for LLM Multi-Step Reasoning , |
Internal, Sequential |
✗ | OREO | ✗ | Beam Search | Value Function | ✗ | Math, Agent |
Pass@1, Success Rate |
| DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , |
Internal | warmup, GRPO, Rule-Based |
✗ | ✗ | ✗ | ✗ | Math, Code, Sci |
Pass@1, cons@64, Percentile, Elo Rating, Win Rate |
|
| s1: Simple test-time scaling , |
Internal | distillation | ✗ | Budget Forcing | ✗ | ✗ | ✗ | Math, Sci |
Pass@1, Control, Scaling |
| O1 Replication Journey: A Strategic Progress Report – Part 1 , |
Internal | imitation | ✗ | ✗ | Journey Learning | PRM, Critique |
Multi-Agents | Math | Accuracy |
| From drafts to answers: Unlocking llm potential via aggregation fine-tuning , |
Internal, Parallel |
imitation | ✗ | ✗ | ✗ | Fusion | ✗ | Math, Open-Ended |
Win Rate |
| Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Though , |
Internal, Hybrid |
imitation, meta-RL |
Think | MCTS, A* |
PRM | ✗ | Math, Open-Ended |
Win Rate | |
| ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates , |
Internal, Sequential |
✗ | PPO, Trajectory |
Thought Template Retrieve | ✗ | ✗ | Math | Pass@1 | |
| L1: Controlling how long a reasoning model thinks with reinforcement learning , |
Internal | ✗ | GRPO, Length-Penalty |
✗ | ✗ | ✗ | ✗ | Math | Pass@1, Length Error |
| Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions |
Internal, Hybrid |
distillation, imitation |
✗ | Reflection Prompt | MCTS | Self-Critic | ✗ | Math | Pass@1, Pass@k |
We understand that an individual's strength is limited. I hope our survey provides an open and practical platform where everyone can share their experiences in TTS practice within the community we are building. These experiences are invaluable and will benefit everyone. If the guidelines you provide are valuable, we will include them in the PDF version of the paper.
@misc{zhang2025whathowwherewell,
title={What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models},
author={Qiyuan Zhang and Fuyuan Lyu and Zexu Sun and Lei Wang and Weixu Zhang and Zhihan Guo and Yufei Wang and Niklas Muennighoff and Irwin King and Xue Liu and Chen Ma},
year={2025},
eprint={2503.24235},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2503.24235},
}
Comments & Discussion